Jobs & Pipelines — Orquestração no Databricks
Esta seção descreve como Databricks Jobs (Workflows) funcionam como motor de automação deste projeto e como encadear os notebooks do medalhão.
Conceitos
- Job (Workflow): definição nomeada de uma ou mais tasks (neste projeto, notebooks PySpark) com dependências, política de retries, agendamento ou disparo manual.
- Pipeline de dados: sequência lógica Extração → Landing → Bronze → Silver → Gold materializada como grafo de tasks; cada execução é um Run com histórico e logs centralizados.
Ou seja: o Job é o mecanismo operacional no Databricks; o pipeline é o fluxo de valor dos dados que esse Job executa de ponta a ponta.
O produto Databricks também oferece Delta Live Tables (DLT) para pipelines declarativos com dependências entre conjuntos de dados. Este projeto prioriza notebooks PySpark orquestrados por Jobs: abordagem direta para o cenário didático (Unity Catalog, volumes e Free Edition) e alinhada ao encadeamento manual validado em sala.
Fluxo de execução (DAG simplificado)
flowchart TD
T0["Task: 00_setup_database.py"]
T1["Task: 01_extracao_to_landing.py"]
T2["Task: 01_landing_to_bronze/landing_to_bronze_delta.py"]
T3["Task: 02_bronze_to_silver/silver.py"]
T4["Task: 03_silver_to_gold/gold.py"]
T0 --> T1 --> T2 --> T3 --> T4Componentes do Job (referência)
| Sequência | Notebook | Descrição |
|---|---|---|
| 1 | notebooks/00_setup_database.py |
Cria BibliotecaDb e dados de exemplo |
| 2 | notebooks/01_extracao_to_landing.py |
BibliotecaDb → Landing (CSV no Volume) |
| 3 | notebooks/01_landing_to_bronze/landing_to_bronze_delta.py |
Landing → Bronze (Delta) |
| 4 | notebooks/02_bronze_to_silver/silver.py |
Bronze → Silver (Data Quality) |
| 5 | notebooks/03_silver_to_gold/gold.py |
Silver → Gold (Kimball) |
O notebook notebooks/05_destruir_ambiente.py é utilizado apenas para reset manual do ambiente e não faz parte do Job produtivo/didático comum.
Por que Jobs automatizam o projeto
- Dependências explícitas: cada camada só roda após a anterior concluir com sucesso.
- Reprodutibilidade: o professor ou qualquer membro da equipe executa o mesmo grafo de tasks, sem depender de ordem manual esquecida.
- Observabilidade: status por task, logs e tempos no painel de Workflows.
- Agendamento opcional: após validação, é possível agendar execuções recorrentes (por exemplo, diárias) sem alterar o código dos notebooks.
Em contraste com execuções ad hoc no cluster, o Job transforma o conjunto de notebooks em um processo de dados governado.
Evidência no workspace: dbutils.notebook.run e Notebook Workflows
O exemplo abaixo mostra um notebook que dispara os estágios em sequência (dbutils.notebook.run) e o painel Notebook Workflows com execuções Succeeded, confirmando o encadeamento Extração → Landing → Bronze → Silver → Gold no Databricks.
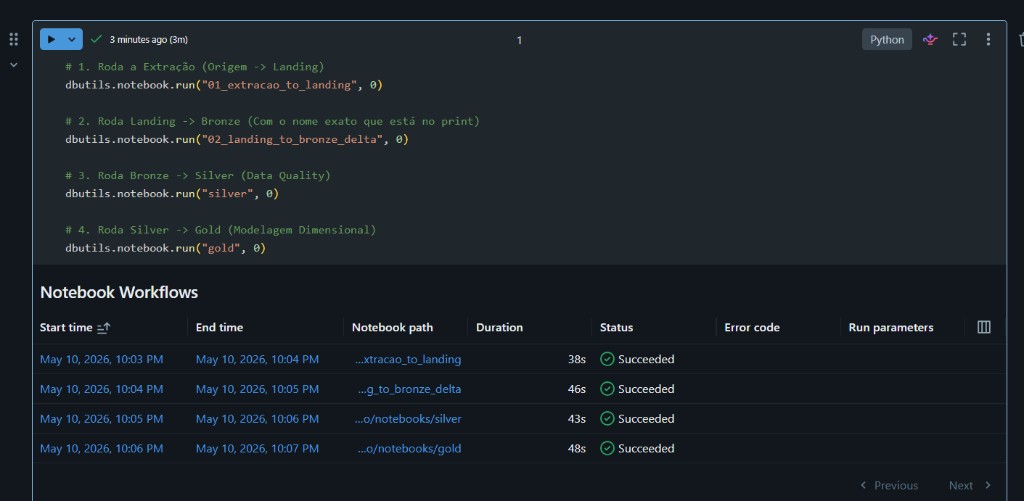
Criando e configurando o Job no Databricks
Siga os passos abaixo para replicar o pipeline no workspace (ajuste o caminho /Workspace/... ao local onde o repositório ou os notebooks foram importados).
1. Publicar os notebooks no Workspace
- Abra o Databricks e faça login no workspace correto.
- Coloque os arquivos
.pyem um caminho acessível pelo Job, por exemplo: - Repos: clone do repositório Git → caminho tipo
/Repos/<usuario>@dominio/trabalho3ed-medalhao/notebooks/... - ou Workspace: pasta criada manualmente →
/Workspace/Users/<usuario@dominio>/trabalho3ed-medalhao/notebooks/... - Confirme que cada arquivo aparece como notebook (Databricks aceita
.pycom células# COMMAND ----------).
2. Criar ou escolher compute
- Em Compute, crie um cluster compatível com Unity Catalog (conforme sua conta) ou configure um Job cluster ao montar o Job.
- Anote o nome ou definição do cluster — você vai referenciá-la em cada task.
Na Free Edition, prefira um cluster compartilhado já existente ou Job cluster pequeno para limitar custo; mantenha políticas de auto-termination.
3. Criar o Job
- No menu lateral, abra Workflows.
- Clique em Create Job.
- Em Job name, informe por exemplo
pipeline_medalhao. - Em Maximum concurrent runs, use
1para evitar sobreposição de cargas no mesmo conjunto de tabelas.
4. Adicionar tasks em sequência
Para cada notebook da tabela de componentes, clique em Add task:
- Task name: nome curto (
setup,extracao_landing,landing_bronze,silver,gold). - Type: Notebook.
- Source: Workspace (ou Git / Repos, conforme onde os arquivos estão).
- Path: selecione o notebook correspondente (ex.:
.../notebooks/00_setup_database.py). - Cluster: escolha o cluster criado na etapa 2 (ou “Existing cluster” / “Job cluster”).
- Depends on: para a primeira task, deixe vazio; para as demais, selecione a task imediatamente anterior para formar a cadeia linear.
Repita até incluir as cinco tasks na ordem: setup → extração → bronze → silver → gold.
5. Parâmetros opcionais por task
- Timeout: configure tempo máximo por task (por exemplo 60 minutos) conforme volume de dados de teste.
- Retries: opcional — para dados didáticos costuma bastar zero ou uma nova tentativa na task de ingestão.
6. Notificações e agendamento
- Na configuração do Job, em Notifications, adicione e-mail em falha/sucesso se desejar alertas.
- Em Schedule, opcionalmente defina cron ou intervalo (por exemplo diário) após validar uma execução manual bem-sucedida.
7. Salvar e validar
- Clique em Save (ou Create).
- Use Run now para uma execução de ponta a ponta.
- Acompanhe Runs → instância do run → cada task deve ficar Succeeded em ordem.
Executando o Job manualmente
- Acesse Workflows → Jobs.
- Abra
pipeline_medalhao(ou o nome definido). - Clique em Run now.
Monitoramento
Status típicos:
- Succeeded — todas as tasks na dependência completaram.
- Running — execução em andamento.
- Failed — ao menos uma task falhou (ver log da task).
- Skipped — task não executada por falha upstream.
- Timed out — tempo máximo atingido.
Boas práticas
- Prefira job clusters ou clusters com auto-termination para economizar créditos na Free Edition.
- Configure notificações para falhas em ambientes compartilhados.
- Valide contagens ao final de ingestão e Silver conforme os próprios notebooks imprimem nos logs.